#1 - 2017-11-16 20:22
W
排序似乎和相關度沒有關係:

結果和標籤一點關係都沒有吧。
推薦用「 BM25 」做排序, 效果應當會好很多。
好處是既能考慮到標籤在一個作品中的重要性, 又能考慮到作品本身的人氣。
詳見: https://en.wikipedia.org/wiki/Okapi_BM25
=== Updated ===
成品的模樣
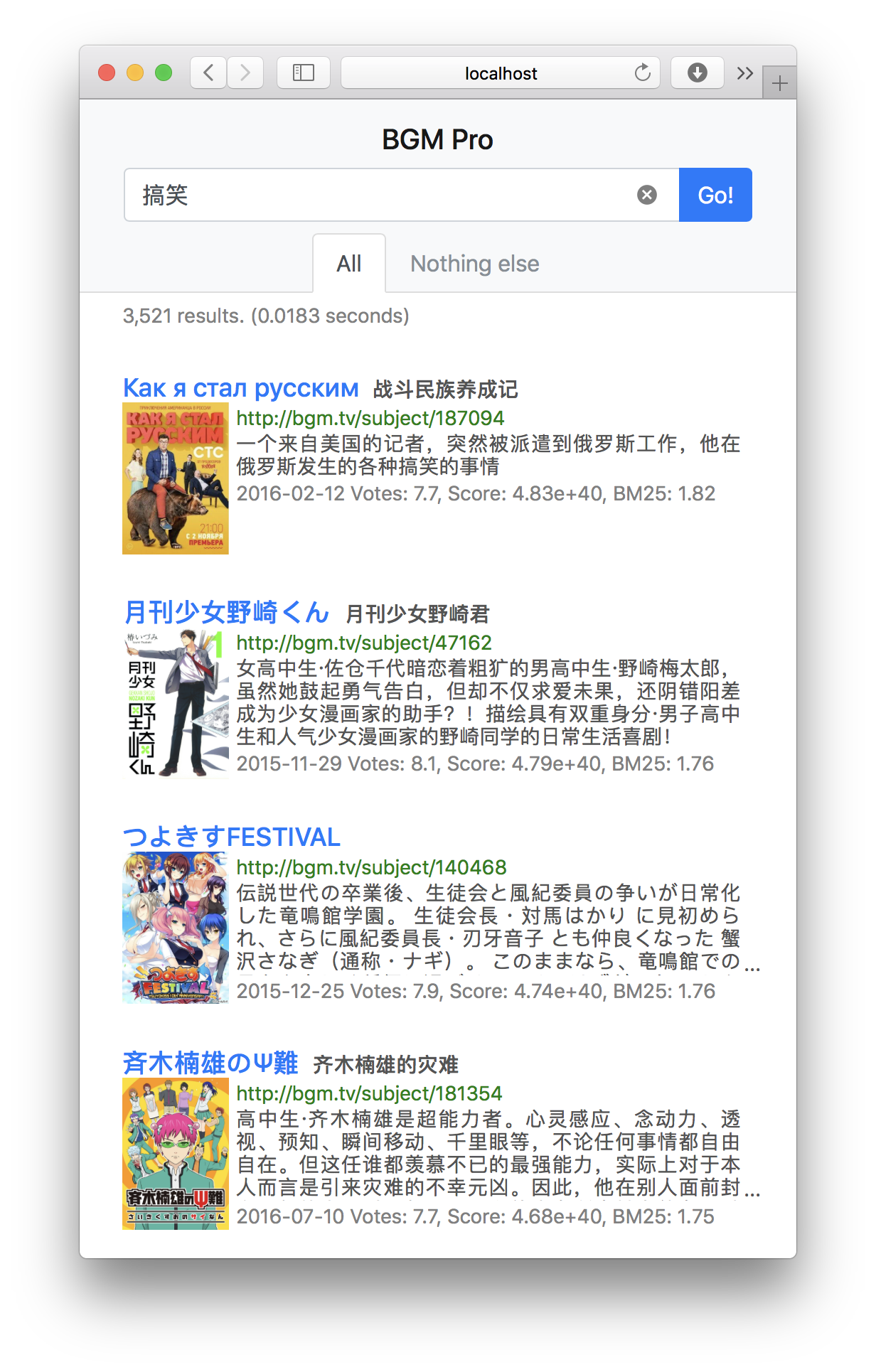
(網站未上線)
結果和標籤一點關係都沒有吧。
推薦用「 BM25 」做排序, 效果應當會好很多。
好處是既能考慮到標籤在一個作品中的重要性, 又能考慮到作品本身的人氣。
詳見: https://en.wikipedia.org/wiki/Okapi_BM25
=== Updated ===
成品的模樣
(網站未上線)
作為解釋:
BM25 會用一種辦法權衡 TF 和 IDF
TF 指的是 用戶打tag的多少
IDF 指的是 同一個tag被作品使用的情況
簡單得總結起來就是:
用戶對一個作品的同一個某個Tag打得越多,在這個Tag的排名越靠前
但是同一個作品中其他Tag的數目越多,那麼在這個Tag的排名越靠後
總體來說一個作品被用戶Tag的數目越多,那麼這個作品會越靠前
其他還有對多Tag的支持等現在的tag頁面不支持的功能,不過「能做到的先做到,為未來做好準備」順手加上去也不錯。
BM25 的確不會產生很好的結果, 但比起「按照時間」「按照名稱」這樣的排列要有意義得多。
在此之上的修正會有許多,例如「根據發布時間調整權重」,「根據人氣 Rank 調整權重」,如果首先讓結果變的有意義起來,那這些錦上添花的修正再加上也是非常不錯的吧。
因為點開一個標籤頁面的時候, 相當於是在標記著這個標籤的千千萬萬個作品中挑出20個。
那麼也就是實際上是:
對千千萬萬個作品按照一定標準排序,然後挑出前20個。
「為什麼這是排序問題?」
是在自問自答地解釋
「為什麼『頁面的結果質量不好』實際是一個排序問題?」
並不是質疑「為什麼Bandumi不提供排序?」。
這邊並沒有這樣的質疑。
為了解除可能的疑慮,事先聲明:我也沒有在質疑現有的3個排序方法存在意義。
事實上我認為有名稱排序、時間排序、總體排名排序對於想要把整個Tag下所有內容都整理/看一遍的用戶來說,存在意義是很有必要的。
我去看了一下找到了這裡不存在的功能:
「按评价数排序」
我想 BM25 一定會是一個不錯的開始。
雖然會加上一點額外的功能,但是考慮到一些原因,在中國的訪問可能速度不快。
請不要期待地敬請期待吧。
这个网站不会被告很大程度上是因为不是盈利性质的
如果直接产生利益的话可能就会有版权问题了...
几天后...
-喂喂!这些脏兮兮的虫子都爬烂我的衣服了,快让他们走开!呜呜呜...
想以每小時更新的頻率來爬取內容,但又擔心負載會對服務器造成壓力。
BM25 ⬅️單是這口感覺還是有些稀薄。
參考 Google 搜索的響應時間在半小時內(能夠搜索到半小時內互聯網上發生的事情), 我想它們爬蟲的最高頻率應該更高吧。(不論主動被動)
Google 能做到更好當然還有其他史詩級魔法的幫助,不過我相信(能夠做到)高頻率也是其中一個非常有影響力的因素。
- 首先关于你的内容
「最坏情况128条/秒」以及「虽然不想造成压力,但是因为懒可能还是不管速度」这两条,你是否还没意识到这请求频率过高了?参照7月以来大概有3500活人的说法(来源),这一个功能就相当于全部活人每30秒请求一次,24小时不间断。或者你可以算下一天你会占掉服务器多少流量和带宽。
- 其次关于「人少的时间」
参考人的作息时间以及程序判断(后面会说)
- 然后关于频率
30分钟刷新一次,你这么做的结果就是发现没几个条目标签会有变化。你自己也提到了可以根据 timeline 来判断,每分钟更新的动态都没几条,如果只刷新这部分标签,每秒1次都过于浪费。另外有编辑的条目可以以 wiki 页面为判断,只刷新被编辑条目。两者加起来,每分钟也很难到上百条目,即:每秒请求1个条目都可能比较浪费服务器资源。
补:不在 timeline 和 wiki 这两者之间直接点tag的小概率(个人觉得)可以靠低频更新冷条目解决,如 Rくん 所说,3个月一轮问题都不大。虽然你说了增量,不过我怕你一懒就全部刷一遍了
- 关于不想造成压力
我随便说几个,比如可以按照「响应时间」、「出错概率」、「更新的命中率」等来参考。
「响应时间」就不用说了,要是慢了就请降低频率。
「出错概率」同理,要是频繁502等报错,即使不是你的关系,也请降低频率,因为对服务器来说总压力是不小的(也可能是其他非服务器因素)。
「更新的命中率」是比较重要的,你半小时刷新一轮,结果发现就改了几条,emmmm,wtf。所以至少做到请求要是发现没变化,请该条目更新降低频率。
更多的可以自己优化,向着「服务器有什么样的反应是压力大导致的」这个方向即可
最后说一句(以下出于个人主观)
出发点是好的,但要注意做法。「好的出发点」并不能成为「因做法问题而导致的不好的结果」的辩解理由
补:蛮期待标签搜索的优化,现在的体验确实
我想解開一些誤會:
# 30分鐘更新完畢
並沒有在說「30分鐘內把整站都爬一遍」
而是指「30分鐘將本地更新到最新」
所以假設真的「发现没几个条目标签会有变化」, 那樣的話,最佳情況是,在30分鐘之內滿足只有那些條目被(向本地)更新。(後面討論為什麼是「最佳」而不是「固定」)
至於「30分鐘」概念提出的意圖並非設立一個跑分標準,而是為了量化與初步訂下可以確定的指標。
# 對於速度的把握
我發現 BGM 在用 CloudFlare 做反向代理,有預期到 CF 那邊*可能*設置了緩存。
如果是這種情況,總之對於 <1kps 的請求來說, CF 應該可以無痛不養接受下來吧。
這也是考察期的一個重點。
除此之外我也有在觀察 BGM 在那些層面做了緩存。一個發現是「timeline 應該是存在緩存機制的」(後面討論更多)
根據觀察 timeline 的更新似乎存在週期,而且內容會發生聚合/變化。
最糟糕的是 Timeline 並不支持 Paging,也就是說短期內如果發生了大量 events, 那麼就一定會 miss 掉一些 event。
這些增加了難度於,甚至完全阻斷了通過 timeline 來準確獲得更新條目的方法。
這也是為什麼我之前提到 timeline 的時候用的是「參考」的原因。
# 「魔法」
我設想,將 timeline 看作一部分,使用帶有 heuristic 的方法或者使用 ML 的一些辦法來獲取「更新判斷」,不過這些需要時間,我不想在爬蟲的問題上滯留太久是這裡的糾結點。
# 「响应时间」、「出错概率」
都是非常好的建議,非常適合放入「魔法」中呢 (試著插入一個表情但是沒有找到於是括開一點描述一下大概是「安楽が」的感覺)
# 關於「正確請求量」的初期判斷
基準判斷是,對於普通 PC 級別的伺服器來說,10ms 的響應時間應當已經是非常奢侈的請求了。
一個還未考量的因素是 Tag 是否存在緩存。哪怕是數據庫級別的緩存,只要不存在運算,那熱門作品就不會造成很多傷害,較為一般的設計在 2ms 內能夠完整(在伺服器)渲染完畢頁面也是常理中。(即使 PHP 也如此吧)
但是奢侈地認為瓶頸不在流量上也是不當的,雖然除去了很多靜態文件(CSS/JS)的請求,但網頁本身也有不少的流量。這裡有我的另一個糾結點:是否要/怎樣做 Benchmark?
这个先不说,Timeline 会整合一定数据这点,大多数情况下达不到需要 miss 的量,每页最远的条目也是好几分钟之前,所以每分钟一次 timeline 再去重即可。(个人印象中整合了也会简略的显示条目,所以根据条目的 url 还是可以知道作品条目)
即使发现有miss的,你可以到对应用户的 timeline 里面去找,至少用户不会被整合掉,本身这种情况就很少了所以这部分并不会丢失多少数据。
然后加上 wiki 是 5min 刷一次,但是 5min 内新的条目并没多少,列表大多数还是前 5min 甚至更早的时候编辑的,所以反倒是去重比较重要。
至于标签缓存,现在说可能没什么可信度,你做了就会发现,缓存几天关系都不大,根本不会变多少,倒是我觉得自动提取有效的标签比较难。
除去以上部分,剩下你担心遗漏的,通过更新的命中率(每次更新有变化次数/总更新次数)来调整刷新频率即可。
对了,那个初始数据可以让服务器计划任务凌晨两三点开始到早上五六点之间,反正都是睡一觉就好的事,还能减轻负担。好像混入了什么糟糕的言辞
至于用户信息,那个太多了,而且没用,不要爬了
更新的需要在於獲得變化趨勢,這一數據在算法的後續改進(其實也是我想做這個的主要目的)上有意義。
用戶信息是在以上都還不夠好的情況下再加強的(並非主要考慮、計畫上會去做的可能性比較低)
總之目標的最終效果是:
點開標籤第一頁就有想要看卻一直沒發現的作品(目標作品)。
更高目標是:
前三項就是目標作品。
不過不管怎樣我應該不打算經過 CF 訪問了,我找到了 BGM 所在的伺服器,準備從他家旁邊直接接一根管子插進去 OwO
2.
而且 miss 發生了就沒有除了整站爬取以外的 有保證的 獲取方法。
不過不管怎樣,根據「timeline 有 cache」這一觀察, 存在可能: miss 不管使用什麼頻率獲取 timeline 都無法避免。
如果是上述情況,就需要 timeline 以外的方法來獲得 updates。
(此處跳出 timeline 話題)
3.
4.
5.
6.
至於「為什麼少的標籤不需要去掉」,見我對基礎的 BM25 算法原理解釋: #1-2
7.
之前我自己說到的 updates 可能需要用 ML 的方法來做, 我仔細思考覺得這樣並不正確。
有簡單的方法可以預測 trends,包括對歷史 update 的 smoothing 。
現在我的考慮是用較慢的速度全體爬來保證更新能夠被獲得,用一些 timeline 來獲得 updates。
當 timeline 發生 possible miss 的時候, 再用預測來 cover。
以上
感謝你的建議與反饋,我將在近日內儘快展開計畫。
我的重點不在爬蟲上,也不想在爬蟲上。
預計3天後開始
# 現在的步驟:
- 爬蟲的各種實驗
- 成本的核算
# 預期的目標
- 在半個小時內將所有作品頁面爬下來
# 正在躊躇的計劃
使用「魔法」製作出支持較為智能的增量抓取爬蟲
当然如果你没打算改变想法的话,我希望你选个没什么人访问的时间,以免影响其他用户体验
現在是 230714 條,半個小時全部爬完的話 就是一秒 128 條。
關於這個必要性的討論放到 #5 裡吧,這裡保持在「需要每小時更新的情況」。
雖說「半小時更新完」是一個比較嚴苛的要求,不過也只是把它當作「最壞的情況來看」因為:
- 對於一次性爬完,並不需要那麼嚴格的時間條件。
- 對於之後的「更新」可以使用魔法(增量更新)完全不需要整站重爬。
魔法越神奇(更新選擇越精準),需要爬的內容越少。
只是魔法的神奇也就意味著更加複雜。
現在魔法的核心屬性是:
「哪些作品會被頻繁地修改 tag?」
有的輔助信息是整站的時間線(https://bgm.tv/timeline)。
但要是一不小心心癢手抖偷懶不想寫限速, 不,我是說萬一的情況,可以給我一個參考的「人少」的時間段嘛?
萌新剛來不怎麼了解行情。
用戶信息可以很大程度上完善檢索結果,但是涉及到的隱私問題以及「技術設計可能花費太久」的問題就暫時放下了。
如果初期的檢索結果不佳的話還是會繼續考慮的吧。
對了,雖然我前兩天剛註冊,ID 應當是 378785。
比起總作品數目要多呢。(未能插入的表情:?)
速度可能卡在 MySQL 的 IO 上, 如果使用 NoSQL 系列效果可能會更好。
不過這一點也要看你存儲多少數據,如果IO量非常大,比如將整個頁面存取下,你可能不能使用數據庫,要使用別的方法。